这些部门要开始裁员了… | 聊聊ChatGPT的新功能
首发微信:https://mp.weixin.qq.com/s/TqGQVF52Bpd7M86aocA6NA
ChatGPT全面开放了Code Intepreter功能,我试用后觉得,对不少公司来说,有几个部门的人手可能要缩减一波——
- 大厂里的数据分析/BI部门
- 金融机构里的风控部门
- 负责数据可视化的VisualAid部门
用法也相当简单:开通ChatGPT Plus后,在「Setting and Beta」里面打开Code Intepreter。
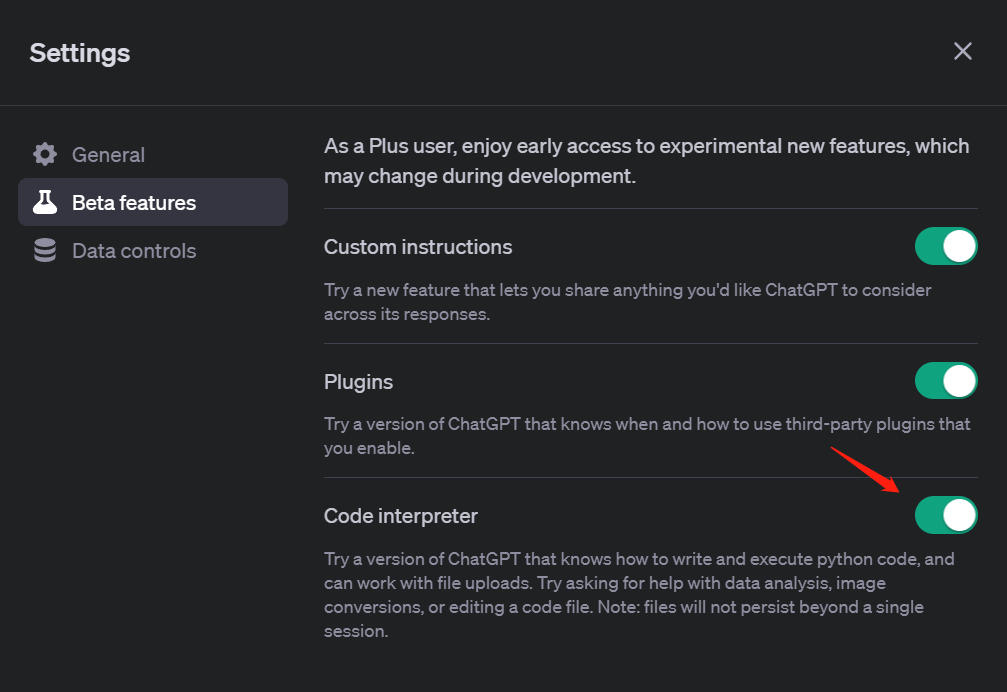
之后在GPT-4选择Code Intepreter模式就可以使用了——

然后在输入栏旁边会多出来个「+」按钮——
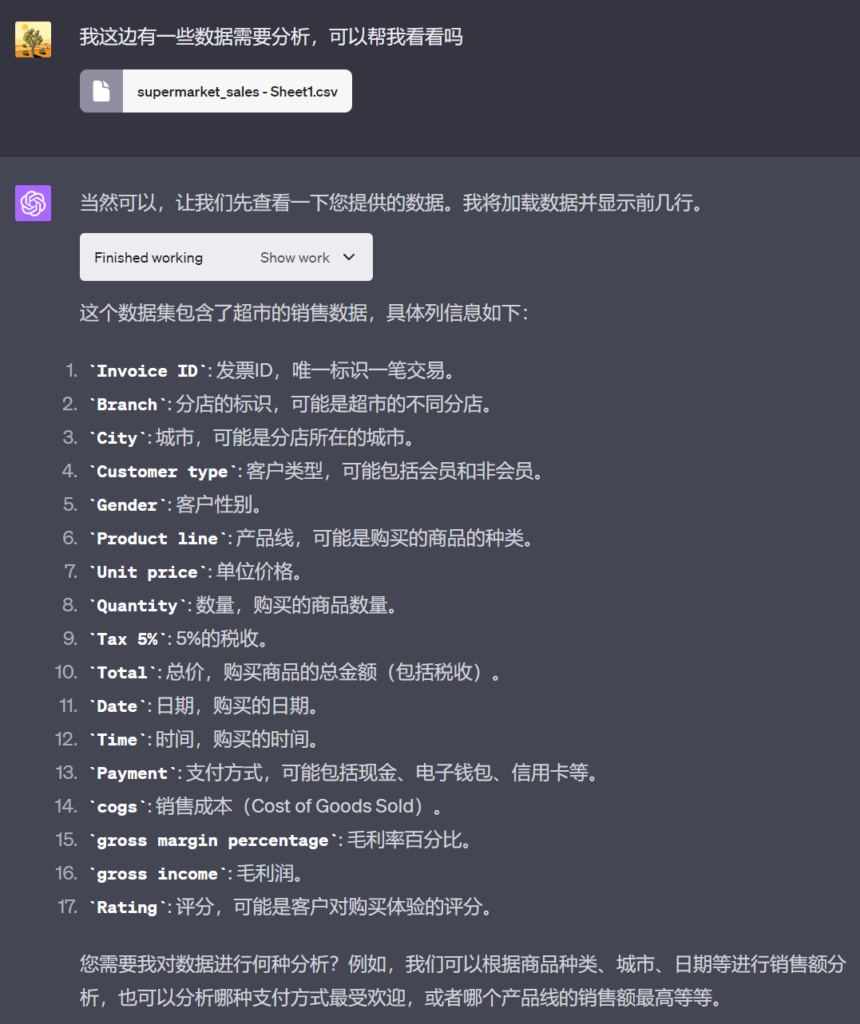
接着,我在github随手找了个超市销售的数据集(来自用户sushantag9)。这个文件大概长这样——

我把数据集丢给了ChatGPT,它很快读懂了这个excel每个数据都是什么意思——
然后我给了它足够的自由度——直接问它这数据能用来干嘛。
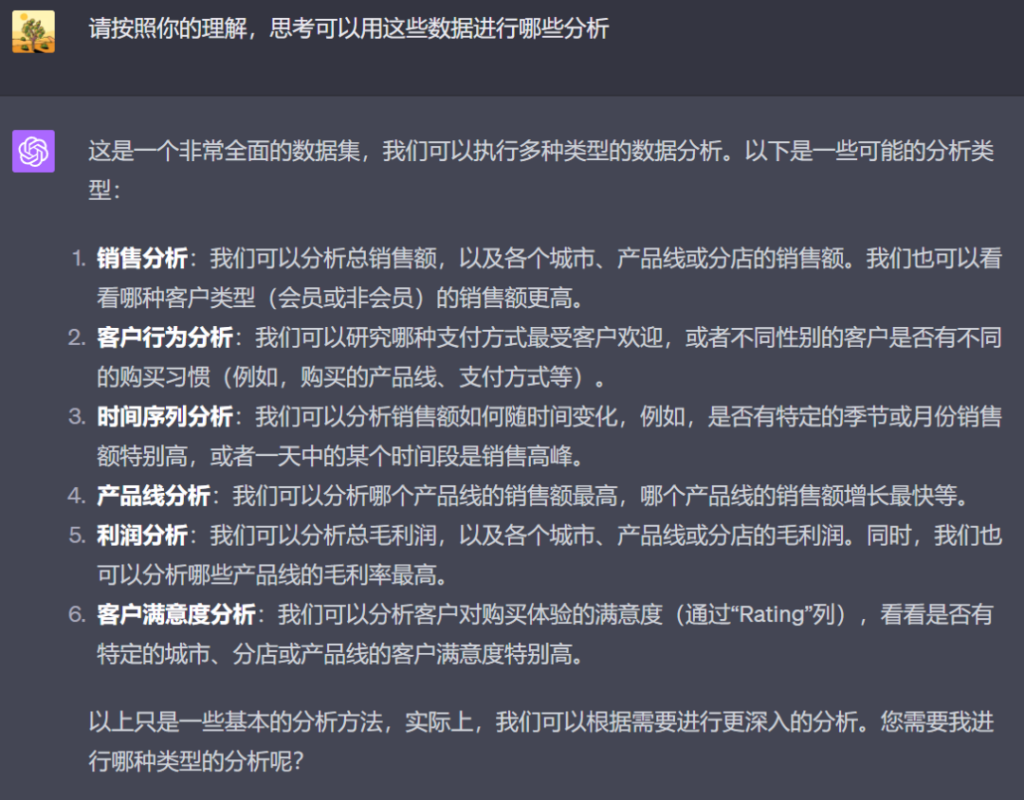
它给出的方向都还挺靠谱的。接着,我让它帮我分析顾客的购买习惯,它直接得出了几个维度的结论——
它甚至还制作了图表。不过图表是英文的,所以我让它翻译成中文。结果出来的都是乱码。
我猜想可能是编码问题,或者是字体问题——
跟它聊完后,发现主要是因为它的环境缺中文字体,所以我跟它要了段代码,在自己的电脑上用Visual Studio Code跑了跑。结果很顺利地生成了中文的图表——
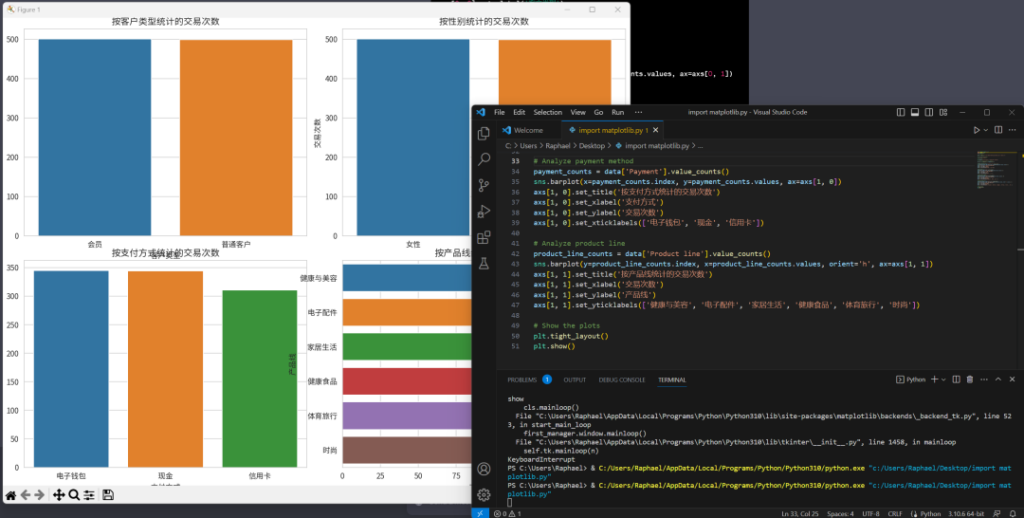
而这一切只要5分钟不到就完成了。
到这一步,我已经觉得很惊艳了,不过接下来让我更加吃惊。
我想做3个维度的数据分析,想在视觉上先看看感觉,于是我让它生成了个3D散点图。
它也很轻松做到了——
我突发奇想,问它能不能做成是交互式网页。它直接调用了plotly,然后提供了网页文件。
下载后可以直接在浏览器打开,做得特别好。

紧接着,我又在github找了个贷款数据集(来自用户ParthS007)。里头有很多贷款的基本信息和审批数据。我把数据喂给了chatGPT,然后它很快又读懂了数据集——
接着我同样让它帮我看看这些数据能做什么分析——
然后我提了个需求,让它帮我建立一个随机森林预测模型,预测贷款是否被批准——
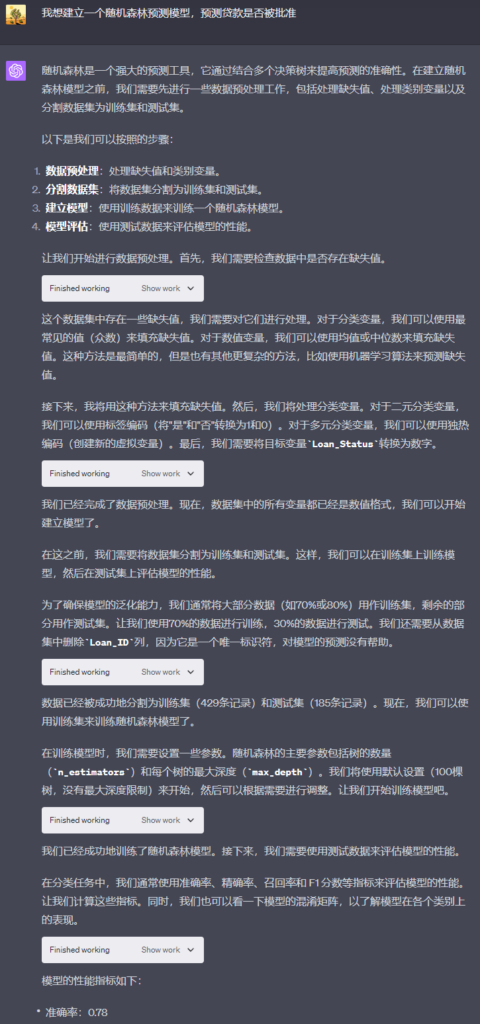
它一步步地进行数据预处理、分割数据集、建立模型,然后顺手帮我做了模型的评估。它生成了一个准确率78%的模型,而且支持直接导出下载。
Mmmm,如果把「贷款是否被批准改为贷款是否违约」的数据,那就是妥妥的风控模型了。
当然,如果数据稍微复杂一点,还是需要自己改改代码的,所以它也没办法完全替代整个部门。
不过想想之前还在甲方打工的时候,为了看月度运营数据,一个BI部门就得有三五个全职的人。
有了这个功能后,后续其实留一两个人就已经挺够了…
我之前也提到过:越市场化的行业,会越快拥抱新工具。而最市场化的互联网和金融领域,可能是最快迎来冲击的。
叠加之前提到的 共同富裕 逻辑,高三学生们怎么选专业好像很清晰了…
(当然,从投资的角度来说可能是件好事:增不了效,但可以降本啊。)
最后说多几句题外话——
最近很多朋友发现某度的文心一X变得好用多了,而且App端也推了不少新功能。不过我向它提问后发现了个有意思的现象——它的答案跟ChatGPT给出来的答案还挺雷同的。让我不禁怀疑是不是用了GPT的答案来做训练。
当然这也不是什么坏事(除了违反了ChatGPT的使用条款)——之前有个叫Vicuna-13B的模型,用的就是用户分享的几十万个ChatGPT对话作为训练样本,号称可以达到90%的GPT-4的能力。Vicuna-13B模型在大语言模型排位赛里,一度仅次于ChatGPT和Google的Claude。
希望我的揣测是错的吧。毕竟只靠抄答案还是很难爬头的。



About The Author
raphael
Analyst, Best-seller writer. Macroeco/ Investment/ Tech